 |
BTree Toolkit | ||||
| Home | Install | Manual | Application | Other Products | |
Rescue
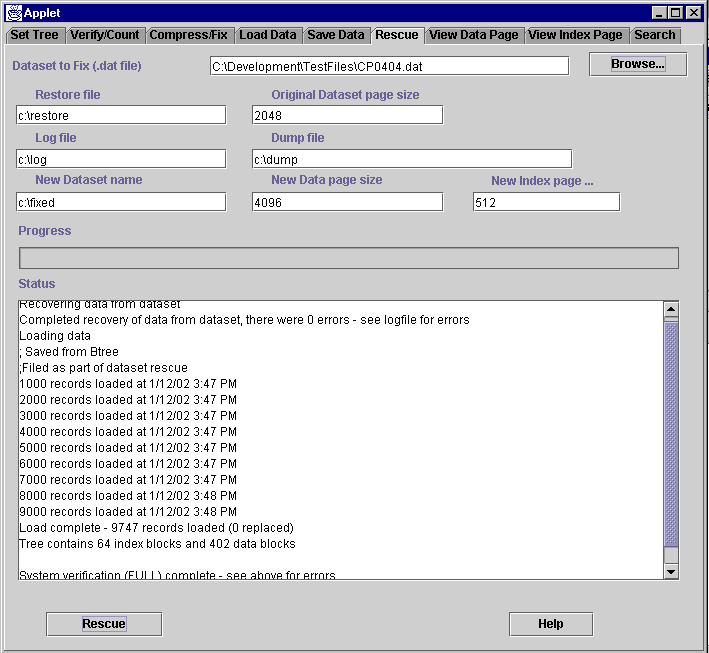
The ‘Rescue’ tab illustrated above is the most complex tab in the toolkit – we here at Virtual Machinery hope that you will never have to use it since the only reason would be that one of your datasets has been very badly messed up! But data in files can be corrupted and nobody likes to lose data – this utility should allow you to maximise the amount of valuable data that you can retrieve from a corrupt BTree file.
In practice all of your data is held in the data (‘.dat’) file of the dataset. A corrupt index (.ind’) file can be rebuilt from any dataset using the compress/fix utility. In this case we are trying to deal with a situation where the data page file has been damaged therefore the first thing we need is the name of your ‘.dat’ file. Since the initial data at the beginning of your file may be corrupt we also ask for the page size of the file. If you know this well and good – if you don’t you may be able to find it by examing the file using a disk editor and the format of the data file (see the original BTree documentation). At the very worst you may have to guess it and keep running the ‘Rescue’ utility until you get a reasonable result.
You also need to provide the paths for three other vital files that the rescue process will require -
- Restore – the restore file is used to store any recoverable data that the rescue process finds – this is simply a Virtual Machinery BTree save file using the Binary format
- Log - This logs everything that the rescue process has done – how many records it recovered from each page, how many pages it had to skip due to errors, how it created the new dataset
- Dump – This provides a dump of each unreadable page in the hope that you might be able to pick out by hand any valuable data that the rescue process could not recover
The last thing that you need to provide is the name of the new data set and the sizes of its index and data pages. This dataset will be filled with the recovered data from the process. Note that you just need to provide the path and the base file name – do not append .dat or .ind. If , for example, you enter NEWFILE then a new dataset consisting of the files NEWFILE.DAT and NEWFILE.IND will be created in the path that you have specified or in the current working directory if no path has been specified. A number of rules govern the index and data page sizes – in summary these are –
Index Page size
- Must be greater than or equal to the minimum index page size allowed
- Must be less than or equal to the maximum index page size allowed
Data Page size
- Must be greater than or equal to the minimum data page size allowed
- Must be less than or equal to the maximum data page size
- Must be greater than or equal to the Index Page size chosen
- Must be an even multiple of the Index Page size chosen
When you start the process by pressing the ‘Rescue’ button the progress of the process will be displayed on the Progress Bar and in the Status Pane. The sequence of events will then be as follows –
- The data file will be read through and the recoverable data saved to the restore file. At the end of this process the status pane will indicate if there were any errors.
- The data will be loaded from the save file and the number of records loaded (both a running total and a final total) shown in the status pane.
- The new dataset will then be verified (full verification) and the results shown in the status pane.
If there were any errors you should look in the log and dump files to see what data may have been lost and to try to retrieve it manually if necessary.
Your new dataset is now ready for use although you may wish to compress it using the ‘Compress’ utility.